


Text-to-speech: exploring generative AI’s talkative side

Robotic no more: the quality of computer-generated voices has rocketed. And voice cloning technology adds to the range of text-to-speech applications for business.
|
Getting your Trinity Audio player ready...
|
Having a computer read to you isn’t new – that’s the reality of today’s text-to-speech apps. But having a computer read to you in a way that’s lifelike enough to listen to is. And then being able to add your own voice to the digital world of text-to-speech pushes the possibilities to another level. Lifelike computer-generated voices are enabling multiple applications for business. And brands are busy exploring the talkative side of having high-quality digital audio assets.
If you haven’t heard computer-generated text-to-speech audio in a while, it could be worth listening to the latest algorithms at work. Some of the most staggering examples of text-to-speech this author has heard can be found on the examples page of generative audio AI developer Suno.ai.

Deep learning and, more recently, generative AI tools have poured rocket fuel onto voice synthesis and the resulting computer-spoken audio is now eerily believable. Under the hood, there’s a lot happening to turn text inputs into spoken words that no longer sound robotic and are much more appealing to humans.
And the payback begins with much greater coupling in the brain of the listener when voices are well understood. “Such neural coupling substantially diminishes in the absence of communication, such as when listening to an unintelligible foreign language,” write researchers Greg J. Stephens, Lauren J. Silbert and Uri Hassonc, based at Princeton University, US, in a study dubbed Speaker–listener neural coupling underlies successful communication [PDF].
No more limits on text-to-speech apps
Having access to high-quality digital voices enables firms to engage audiences in a way that just wasn’t possible in the early days of computer-generated speech. Early digital voices had their origins in silicon designs such as Voice Synthesis Processor (VSP) LPC10 decoding chips produced by Texas Instruments towards the end of the 1970s and into the 1980s. And the highly compressed output, necessary due to memory constraints, limited the market to niche applications.
Today, things couldn’t be more different, and vocal models are convincing enough for overdubbing narration mistakes in recorded audio. And there are numerous Youtube videos that show how quick fixes can be made using text-to-speech applications. In fact, in the not-too-distant future, narrators may have little use for microphones once their voice characteristics have been recorded and transformed into a digital model.
Aesop’s fable ‘The North Wind and the Sun’ is famous linguistically as readers will have pronounced the majority of English phonemes by the time they have read to the end of the passage. ‘The Boy who Cried Wolf’ – twice the length of ‘The North Wind and the Sun’, but with less word repetition – is another popular language analysis text. And these examples hint at how voice cloning and text-to-speech algorithms work.
By recording spoken audio, users – who want to be able to recreate their own voices – provide a training set that’s rich in phonemes (the sonic foundations for building spoken words). Unwanted artifacts and background noise can be removed through preprocessing before performing audio segmentation and feature extraction.
Alternatively, algorithms can be trained on existing audio recordings and compared with transcripts to gather knowledge on how different sounds relate to different words. And once the model has been built, it’s then a case of applying natural language processing to match the typed text-to-speech input with its corresponding audio elements.
Text-to-speech apps for business
Also, reflecting the different ways that each of us pronounces our words, phonemes will exhibit variations in terms of their frequency spectrum, timing, and signal energy, when spoken. And today, there are hundreds of text-to-speech models for users to choose from, including celebrity voices such as Snoop Dogg and Gwyneth Paltrow, and – as mentioned – the option to clone their own voice.
Considering popular apps, and having just mentioned Snoop Dogg and Gwyneth Paltrow, it’s fitting to highlight Speechify, which includes the aforementioned stars to its digital roster of voices. Investors include Richard Branson, and the firm’s text-to-speech for business applications are – according to the Speechify website – trusted by teams at Apple and Google.
But business users wanting to generate spoken audio for training videos, create audiobooks, or have realistic, human-sounding voices read out documents and other company information, have multiple software options to consider.
NaturalReader, which runs straight from the browser, has a free tier and paid options. And the speech-to-text app supports a long list of spoken languages, including variations such as French (Canada), Portuguese (Brazil), and others. Also, testing out the speech-to-text app for this article, you can add an accent to the spoken audio – for example, by selecting a German voice to read a document written in English.

Digital voice heavyweights such as Nuance and IBM have powerful speech-to-text applications for business. And one option here is for companies to develop brand voices – digital assets that listeners will associate with firms and products. Branded audio is big news in marketing, and WPP’s acquisition of sonic branding agency Amp in April 2023, expanding the global advertising giant’s generative AI design offering, highlights the trend.
There are open source text-to-speech AI models to consider too. Returning to Suno.ai, which has made the model weights of its transformer-based text-to-audio algorithm (BARK) available on the AI and machine learning tool repository Huggin Face, it’s fascinating to explore the possibilities being opened up by the latest research.
Try open-source generative AI text-to-speech for yourself
Previously on TechHQ, we’ve written about how Airbnb for GPUs is helping to cut the price of running generative AI models. And Suno.ai’s BARK is one of the pre-built options available on Monster API, which makes it straightforward for users to see what generative AI text-to-speech can do.
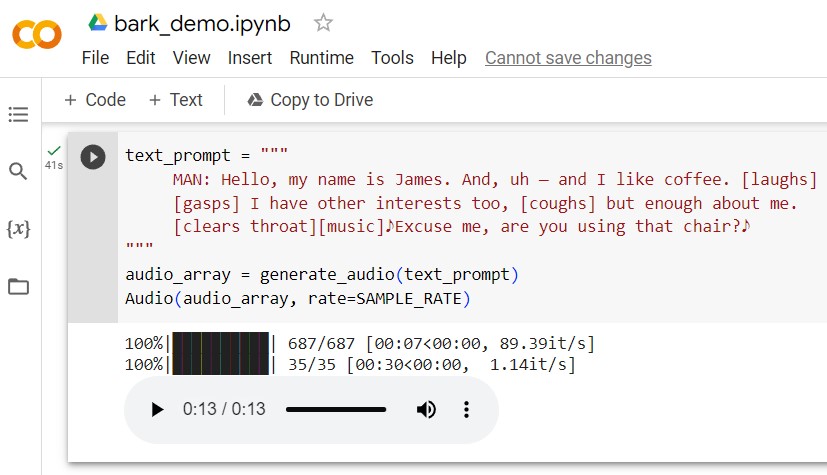
Code demo: Suno.ai’s BARK generative AI text-to-speech model has a demo page that allows users to experiment with different prompts and commands to see what’s possible with next-generation research tools.
Another option is to launch BARK yourself – for example, we’ve had the system up and running on a free Google collab GPU instance using the demo link available on Suno.ai’s GitHub page. And if commercial text-to-speech apps are like looping around an exciting race course, with open-source options users can drive through the barriers and free roam.
BARK’s creators caution that the model output is not censored and is meant for research purposes. One of the big feature differences is that BARK can be prompted to generate non-speech sounds such as laughter, sighs, gasps, throat-clearing, and other actions (the developers are finding more as they dig deeper into what the technology is capable of).
And remarkably, the generative AI text-to-speech tool can even sing – sometimes, at least. You can encourage BARK to be more musical by putting text prompts inside notes to signify song lyrics. Other guidance that can be applied includes [MAN] and [WOMAN] to bias the model towards male or female speakers. And BARK is capable of speaking in Hindi, Japanese, Korean, Russian, Chinese, and other languages.
It’s an impressive list of achievements for a sector that is packed with talent, and the year is only 2023. Hold on tight, text-to-speech applications for business are taking off.

5 March 2024
