


Apple open sources MLX, its machine learning framework

“One of the rare non-Apple laptops seen in an otherwise cool park full of cool people,” by Ed Yourdon is licensed under CC BY-NC-SA 2.0.
|
Getting your Trinity Audio player ready...
|
- Apple silicon now more viable as a machine learning number-cruncher.
- The company open sources its MLX machine learning framework.
- Early figures quote double-digit efficiency and speed gains.
The energy required to run the super-fast ARM-based chips that make Apple’s recent desktop and laptop hardware work is a fraction of that used by x86 chips, which is just one of the reasons why consumers choose Cupertino’s hardware over its competitors. In addition to batteries that can easily power a day or more’s work on a laptop without recharging, applications optimized to take advantage of the computers’ chips often outperform the same binaries running on beefy workstations.

Now, some of those advantages of Apple silicon can be more easily used in the computationally-heavy machine learning world, thanks to the company releasing its MLX machine learning framework under an open source MIT license. The framework supports transformer model language training, image and text creation using Stable Diffusion and Mistral, respectively, and speech recognition with the widely available and extensible Whisper.
Part of the attraction of this change in license for machine learning developers will be the fact that MLX can take advantage of the unified memory system present in M1 and M2 generation chips, which means operations can be carried out on arrays held in memory by either the CPU or GPU, without data having to be moved from one to another. While that saving could be counted in milliseconds, the highly iterative nature of ML computations means that the milliseconds soon add up, so Stable Diffusion, for instance, performs up to 40% faster than PyTorch.
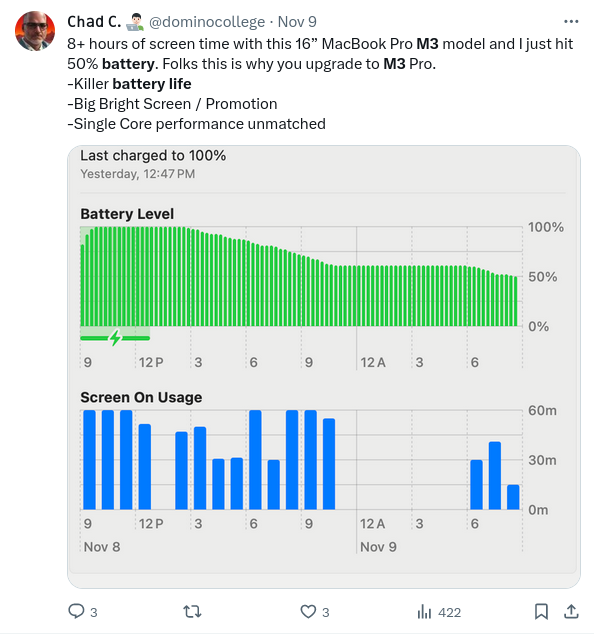
Killer battery life on new MacBooks. Source: X.com
For smaller batch sizes, however, PyTorch has the edge. But as Apple says in its documentation, that’s down to compilation speeds when the model is not held in memory.
MLX supports so-called ‘lazy computation,’ meaning it only materializes an array of data when necessary. Attenuating computation graphs’ arguments does not necessarily start a (slow) compilation process.
The MLX framework is written in C++ and Python and provides API calls that will be familiar already to users of NumPy and PyTorch, so data scientists should be able to move to Apple silicon with a minimum of reworking.

Apple silicon on the data pro’s desk
Developing effective ML models is a time- and resource-consuming process, so speeding the development of new models is a highly attractive proposition. And while Apple silicon-based hardware is not cheap in consumer terms, it can compete with high-end desktop hardware usually found on developers’ and data professionals’ desks.
Apple’s history in open source is mixed: its proprietary macOS is based on BSD, and WebKit has its roots in KHTML, plus it’s the steward of CUPS (the common UNIX printing system), but the company has contributed little back to the open source community. Its decision to throw MLX over the fence, therefore, is a decision that has more to do with the promotion of its hardware than furthering the power of ML by leveraging the power of collectivism.
Putting a machine learning framework in the hands of data scientists that will need its hardware to get maximum benefit sells a few more units, but it’s a long way from that short-term gain to being a power player in machine learning. As those in the area know, the greatest breakthroughs and rapid advancements come from the extensive use of and iterative improvements to open source code – it’s simply not an area in which proprietary engines will outperform crowdsourced methods and frameworks in the medium- to long-term.
Apple’s exit from server hardware around the early 2010s may be considered a poor decision, given that data centers running ARM or RISC V chips can offer similar or better performance to x86 with lower power and cooling bills – given that any application has been recompiled for the architecture. Perhaps the server game is one in which Tim Cook should have stayed: he took over the helm in 2011, the same year Apple stopped producing its XServe rack-mounted server range.


20 June 2024
