



Source: Shutterstock.
|
Getting your Trinity Audio player ready...
|
Misinformation is running rampant across the internet as the risks of AI-derived journalism become clearer.
When China introduced an AI newsreader in 2018, it seemed like a new era of television personalities was beginning. Cut to now, and newsrooms are preoccupied with fighting AI itself.
There are two key areas in which AI journalism represents a threat: plagiarism and misinformation.
The first is evidenced by a move by the New York Times, which updated its terms of services on August 3rd to forbid the scraping of its content to train a machine leaning or AI system.
The new terms of service prohibit web crawlers – which work similarly to LLMs like ChatGPT – scanning content on the NYT site to inform search results. While publishers can see crawlers visiting their sites, they cannot know their exact purposes, whether for search engine optimization or training AI models.
“Most boilerplate terms of service include restrictions on data scraping, but the explicit reference to training AI is new,” said Katie Gardner, partner at Gunderson Dettmer.
Earlier this week, OpenAI launched GPTBot, a web crawler to improve AI models. Although it’s unclear what models would look like, there are, in this caese, penalties for breaking the NYT’s terms.
AI models are reliant on content – including journalism pieces and copyrighted art – as a key source of information for its own output. At times, this output can be a verbatim replication.
In the literary world, authors are banding together to demand that industry leaders obtain consent from, credit, and fairly compensate authors whose work is used for LLM training.
When it comes to changes at the NYT, it’s unclear how AI companies will respond. Discussions are underway between AI companies and major publishers to establish licensing agreements, perhaps like OpenAI’s deal with the Associated Press.
“The arrangement sees OpenAI licensing part of AP’s text archive, while AP will leverage OpenAI’s technology and product expertise,” the two organizations said in a joint statement.
As well as the question of crediting work, there’s debate around how to prevent the dissemination of false information. There’s a perhaps naive public level of trust that takes what AI generates as factual, at least, at present.
In the same tone as a scientific research paper (or large news outlet), an LLM could explain the reasons why the sky might be red to most people.
“Publishers would not want to be associated with that, especially if they’re going to have a licensing deal,” said Pedigo. “Publishers want to make sure that information meets the brand level.”
When the information is harder to verify than the color of the sky, real issues arise. Emily M. Bender, a specialist in computational linguistics who co-authored an infamous essay about LLMs, was caught out by an image of a baby peacock on Facebook.
Scrolling the social media site on her phone, she thought the photo was “adorable!” and shared it. It wasn’t long before her friends pointed out it was a synthetic image – generated by AI.
The spread of misinformation and fake news was arguably an issue on Facebook long before AI hit the mainstream. However, what’s alarming is that Bender’s Google search for a ‘real’ image of a baby peacock turned up a mix of results – including AI generated ones.
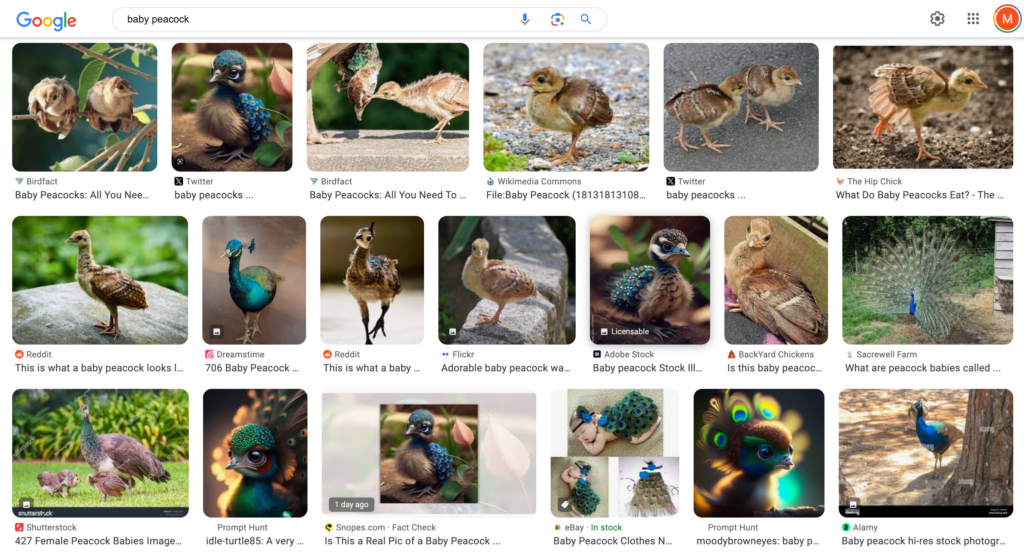
Screenshot of the image results when we searched “baby peacock” on Google. Taken Aug. 17.
Bender’s work regards AI’s production of misinformation, as “the equivalent of an oil spill into our information ecosystem.”
She writes that “the more polluted our information ecosystem becomes with synthetic text, the harder it will be to find trustworthy sources of information and the harder it will be to trust them when we’ve found them.”

Screenshot of an image of a “chonky” parrot posted to Instagram by @discoverwildlife. The caption does state that the photos are edited.
Being able to distinguish between AI and fact is a skill that is critical to navigating the online world – and not one that many have. Until more is done to regulate the use of AI, perhaps it’s just as well that sites like the NYT are making it harder for LLMs to spread their spiders across the internet.



20 June 2024
