


Micron Technology unveils its most advanced HBM yet as Gen AI proliferates

The HBM3 Gen2 memory will be made available from 2024 onwards. Source: Micron Technology
|
Getting your Trinity Audio player ready...
|
- Micron Technology said the improvements reduce training times of large language models like GPT-4 and beyond while delivering efficient infrastructure use for AI inference.
- The HBM3 Gen2 memory will be made available from 2024 onwards.
In the current era of generative AI, High Bandwidth Memory (HBM) is emerging as the preferred solution for overcoming memory transfer speed restrictions due to the bandwidth limitations of DDR SDRAM in high-speed computation. In fact, since the emergence of ChatGPT and services alike, strong growth in AI server shipments has driven demand for HBM, and Micron Technology is grasping the chance to deliver and win market share from its competitors.

For context, findings by TrendForce indicated that the HBM market share is dominated by Korean semiconductor giants Samsung Electronics and SK Hynix, at 90% as of 2022. That puts US memory chip giant Micron Technology some way behind its large competitors, with just a mere 10% market share.
Without mentioning the intention to grab a larger market share, Micron Technology today announced an 8-high 24GB HBM3 Gen2 module. Micron is dubbing it the most advanced in the market, and its newest HBM3 will be able to speed up the development of generative AI.

Micron’s announcement via Twitter
Like all memory, HBM advances performance improvement and power consumption with every iteration. Take generative AI, for instance; that alone holds a tremendous need for much higher HBM. That is why, according to market experts, HBM is a segment of the memory industry that is set to grow by leaps and bounds thanks to the advent of generative AI.
Therefore, to catch up on its major competitors in the segment, Micron Technology decided to tease the industry’s first 8-high 24GB HBM3 Gen2 memory with bandwidth greater than 1.2TB/s and pin speed over 9.2Gb/s for AI accelerators and high-performance computing (HPC).
In a virtual press briefing on July 27, the company said it has begun sampling the HBM3 Gen2 memory, which, according to Praveen Vaidyanathan, VP and GM of Micron’s Compute Products Group, is up to a 50% improvement over shipping HBM3 solutions.

LLM focus: 50% higher memory capacity results in faster training compared with current solutions. Source: Micron
“With a 2.5 times performance per watt improvement over previous generations, Micron’s HBM3 Gen2 offering sets new records for the critical AI data center metrics of performance, capacity, and power efficiency,” he added.
Most importantly, these Micron improvements reduce training times of large language models like GPT-4 and beyond, deliver efficient infrastructure use for AI inference, and provide superior total cost of ownership (TCO), Micron said in its statement.
Micron Technology in the age of ChatGPT through HBM3 Gen2
Because of its costs and complexity, HBM was only a tiny niche market until this year. Research publication Trendforce forecasts HBM demand will soar by 60% this year, with at least another 30% growth forecast for 2024. That being said, Micron decided to develop HBM3 Gen2 with performance-to-power ratio and pin speed improvements critical for managing the extreme power demands of today’s AI data centers.
YOU MIGHT LIKE

China imposes chip sales restrictions against Micron
“The improved power efficiency is possible because of Micron advancements such as doubling of the through-silicon vias (TSVs) over competitive HBM3 offerings, thermal impedance reduction through a five-time increase in metal density, and an energy-efficient data path design,” the company’s statement reads.
The Micron HBM3 Gen2 solution also addresses increasing demands in generative AI for multimodal, multi-trillion-parameter AI models. “The training time for large language models is reduced by more than 30%,” Vaidyanathan explained.
Additionally, he added that Micron’s offering unlocks a significant increase in daily queries, enabling trained models to be used more efficiently. “Micron HBM3 Gen2 memory’s best-in-class performance per watt drives tangible cost savings for modern AI data centers. For an installation of 10 million GPUs, every five watts of power savings per HBM cube is estimated to save operational expenses of up to $550 million over five years,” he shared.
Vaidyanathan also told the media during the virtual press briefing that the foundation of Micron’s HBM solution is its industry-leading 1β (1-beta) DRAM process node, which allows a 24Gb DRAM die to be assembled into an 8-high cube within an industry-standard package dimension.
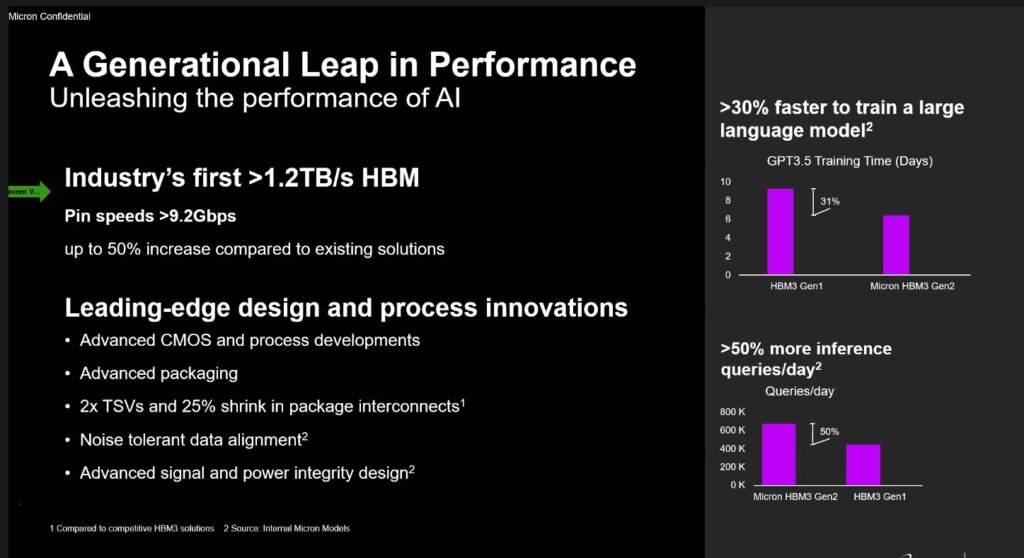
Industry’s first >1.2TB/s HBM. Source: Micron
It’s also worth mentioning that Micron will be working on an upgrade – a 12-high stack with 36GB capacity – which will begin sampling in the first quarter of calendar 2024. Vaidyanathan said Micron provides 50% more capacity for a given stack height than existing competitive solutions.
Micron has developed what it describes as a “breakthrough product” by leveraging its global engineering organization, with design and process development in the United States, memory fabrication in Japan, and advanced packaging in Taiwan. When asked if the products, once ready in early 2024, will be made available for its clients in China, Micron did not respond.
The HBM3 Gen2 product development effort will be through a collaboration between Micron and TSMC. “TSMC has received samples of Micron’s HBM3 Gen2 memory and is working closely with Micron for further evaluation and tests,” Micron noted.

Micron’s HBM roadmap


20 June 2024
