


Ensure Business Continuity with a Purpose-built Data Protection Solution for HCI

The increased public awareness of the realities of the effects of a successful malware attack – especially ransomware – has likely led to some pointed questions being asked of IT leaders in the last twelve months or so. Inquiries about preparedness and the ability of the IT department to ensure business continuity and recover IP after an attack should have ensured some double-checking of disaster recovery policies, cybersecurity measures, and recovery from ransomware procedures.
However, it should be noted that in many cases, disaster recovery procedures are not sufficient for the unique challenges that a ransomware strike poses. Without fully air-gapped backups, for instance, months of archives may already be infected. Rolling-back merely restores the problem in those instances.
Secondly, organizations that use hyperconverged infrastructure (where network, storage, and compute are abstracted and software controlled) are more complex to recover and could rely on fragile scripts and a mixed bag of recovery solutions. In short, backup and recovery policies created even three years ago may not be effective on either count.
Most IT departments practise their data recovery routines to test procedures that prove their effectiveness in providing data availability and business continuity. The idea is that any places where recovery processes are lacking can be addressed before they have to be used in the event of an attack or disaster.
What will have become apparent is that in situations where HCI (hyperconverged infrastructure) is at the core of the IT stack, and/or recovery from ransomware is tested, re-piecing together a working environment from an extraordinary event can be highly complex without proper preparation.
That’s especially true when recovery procedures comprise several parts – some Bash scripts running rsync, some ZFS/BTRFS snapshot recoveries, Nutanix config recreation, and half a dozen more besides. Until the organization gets to a particular size, there’s usually the “hit by a bus factor” too: should the resident expert (typically the IT Lead) not be available, their colleagues would struggle to hit the required times to recover and return to production metrics.
Looking at the situation objectively, it’s incongruous that on the one hand, the enterprise’s IT provision is – thanks to hyperconvergence – an automated, elastic, scalable and malleable resource, while recovery from ransomware involves manual script triggering, multiple tools’ GUIs and an intuitive ‘feel’ for how the business’s systems need to fit back together. There is, however, a solution.
In a hyperconverged environment, the ideal would be for teams to use the same tooling for data recovery that they use daily to manage the resources available to the business. The HYCU Protégé platform offers data protection as-a-service that helps companies recover application-consistent data across resources distributed from on-premise to multiple clouds and a broad range of as-a-service platforms.

Source: Shutterstock
In many cases, companies aren’t aware of the different values of their data silos and, more than likely, are unaware of every data silo’s existence. There will almost invariably be data that needs better prioritization for recovery but doesn’t get it because of constraints on the types of storage and replication available. Worse, too, without any auditing, some valuable IP may not even register on IT’s consciousness.
These are the areas in which Protégé excels. It’s fully platform- and storage-agnostic, can discover hidden SaaS apps and data silos, plus it works seamlessly across private and public cloud and the as-a-service applications on which the enterprise depends. It ensures safe backup and recovery of large centralized application data like Office 365, right through highly distributed Kubernetes deployments and everything in between.
Unlike many other BaaS (backup as a service) platforms, HYCU Protégé doesn’t involve the need to retrain staff to accomplish the simplest roll back to a restore point. It uses a common dashboard paradigm, that, thanks to its broad interoperability, will either be the same as, or highly similar to familiar tools. For Nutanix-based topology, for instance, it uses the same interface that already controls the IT resource allocations. There are similar user experiences with VMware and Dell PowerScale, too, to name a couple.
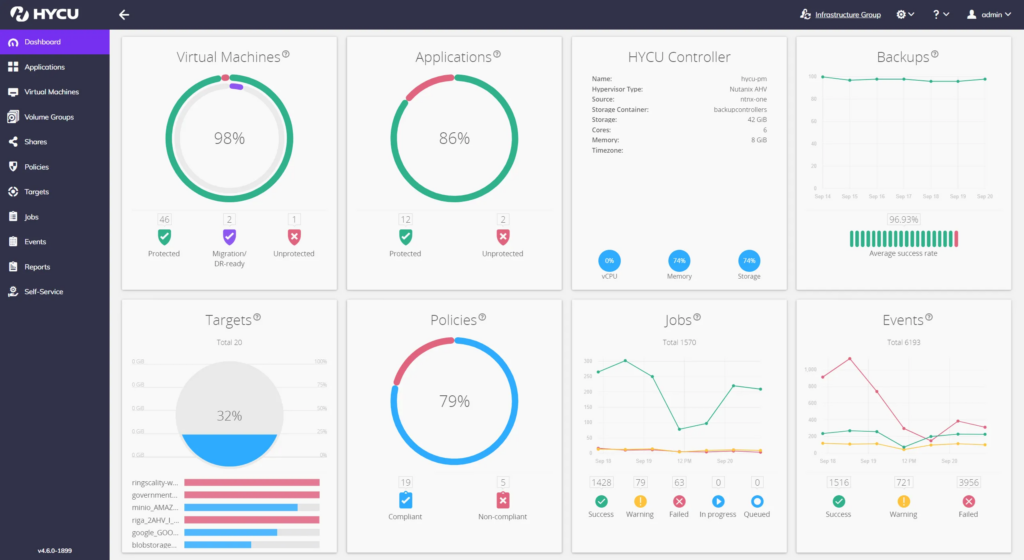
Source: HYCU
The emphasis on GUI and tooling integration means there’s little need for key personnel-specific skills and companies can recover more quickly and reliably in the event of an incident. Data can be stored wherever the company has resources available and can be completely air-gapped to prevent malware from progressing across a company’s network, from on-premise to cloud and everything in-between.
Using an HCI ethos, the Protégé platform can lift and shift in a couple of clicks, meaning data migrations in the course of business are simple and protected en route. As well as opening up another avenue by which IT resources can better serve the business, Protégé also makes tricky data migrations (such as those of live databases) simple to achieve.
Backup and recovery policies simply needs to be set, and HYCU Protégé does the rest. It ensures that data belonging to the organization is discovered, protected and available from any resources the company has access to. Instead of over-provisioning extra cloud compute and storage “just in case”, Protégé lets companies keep costs low. One platform performs full data recovery, only using extra resources for migrations when necessary. There’s a demo available, plus a free trial to try in your specific IT context to see how the platform will integrate with your current HCI and virtualization tooling. Well recommended.



25 June 2024